3 Ways to Fix Null Values
Have you ever experienced this situation or a similar one? You are working with your data, building out some sort of data prep process when something just doesn’t look right? You dive into it and start doing some light QA to put your mind at ease and realize that your calculations are not working properly. You double check them, reading them again out loud to yourself and even tracing them using the expected values, yet you can’t seem to identify what is going wrong and why you are getting a null result. After scouring the internet you finally realize that your result column is the incorrect data type and that is causing the bug. While this can be a painstaking process, you now are more prepared for the next time you prepare your datasets. In this tutorial, I’d like to do a brief breakdown of what null values are, a couple of scenarios you may encounter with them, and ultimately a couple tips to help fix them.
What are null values or “nulls”?
When working with different datasets it is not uncommon to encounter null values or nulls across your schema, but what exactly are these values and how do they happen? Well by definition, null values are non-existent or unknown values and are different from an empty value or 0. You can find or create null values from a variety of different circumstances, to name a few: A union between two datasets with different schemas, an outer-join between two datasets, an incomplete dataset and depending on the tool you are using, an incorrectly syntaxed formula. No matter the way in which you encounter them, this guide is set up to help demonstrate 3 different ways that you can handle null values.
Continue reading with a free account, or login.
Unlock this tutorial and hundreds of other free visual analytics resources from our expert team.
Already have an account? Sign In
By continuing, you agree to our Terms of Use and Privacy Policy.

Impact that nulls can have in your analysis
Before we dive into the tips for addressing nulls, let’s first discuss the impact, both good and bad, that these values can have in your analysis.
The good
You may encounter a situation where you’re creating a visualization or consolidating data that consists of multiple different data sources. With data collected from multiple sources, it is not uncommon to have some discrepancies amongst your datasets, null values can be a great way to help identify holes in your dataset that need to be addressed. They can also assist you in QA as well. As you are going through your dataset, make sure to take notes of where you are seeing null values.
![]()
The bad
While building out your data pipeline you may find yourself using a myriad of different tools like filters, formulas and joins. When working with null values you have to be conscious of how they will behave with the different tools. For example, if you configure a join to connect two datasets and there are nulls in the connecting columns, you could end up expanding and creating duplicates in your resulting data that then becomes messier to try and clean up.
It is important to also be cognizant of how nulls can operate when it comes to formulas and equations. Depending on the software you are using, if you have two columns that you are adding together you could end up with null values as your result, for example: 1 + NULL will result in NULL.
The ugly
If you don’t note or resolve any null values during the data preparation process you can end up in some potentially ugly situations. Imagine you design a dashboard to help support some high-level executives with profits across different regions. You get to the meeting, pull up the dashboard and begin to demonstrate the functionality. As you pull up one of the regions, a stakeholder stops you to ask why one of their most historically profitable regions is showing $0 in profit (Yikes!). As you scramble like a deer in headlights to explain this, you start to lose interest and engagement from your audience, only to discover later on that the lack of profit was due to your profit column being null since the data type was the incorrect one. Explaining this later on can help but might ultimately hurt the confidence that your end users will have in this report going forward. By identifying and addressing null values from the get go, you can save yourself quite the headache in the long run.
How to fix nulls
Now that we have covered the good, the bad, and the ugly about working with null values, let’s shift focus to how we can fix these values while developing. Keep in mind that this will just be three ways that you can try to tackle these, but are by no means the only ways to approach this task. The key way to discern the best strategy is to familiarize yourself with your dataset and your end user so that you can carve out a tailored solution. Let’s dive in:
Fix #1
The first and most straightforward approach is to simply filter these values out of your dataset. Once you have confirmed that the null values are not able to be fixed at the source and are safe to remove, setting up a filter on a column that you know should not be null is the easiest and most dynamic way to ensure future refreshes or runs of a workflow or dashboard continue to get rid of these values without needing any manual intervention. An example of this might be if I was working with patient medical records and I know that every patient should have an ID, then it is safe to assume that the “Patient ID” column should never be NULL and if I run into a case where that happens to be true, then I would want that row removed from my dataset.
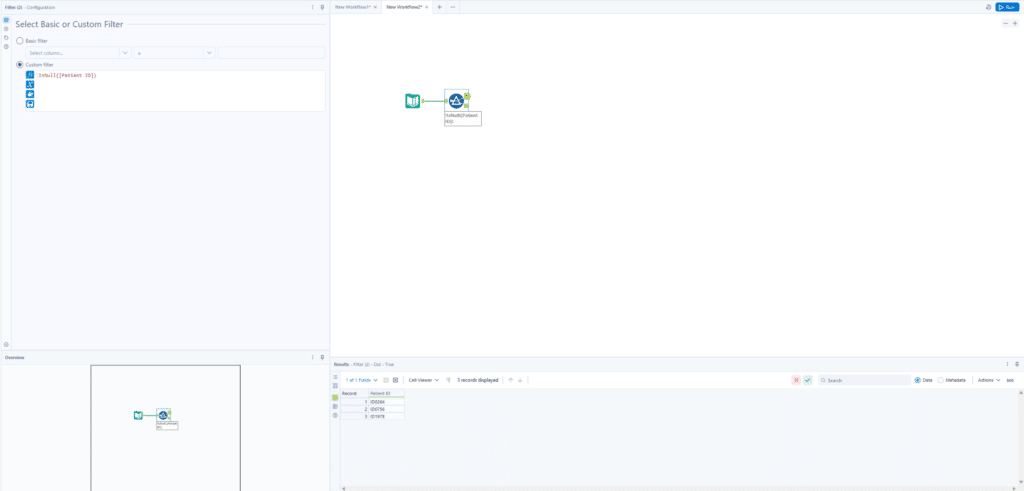
To help better illustrate this, here is an example of the syntax you would add to a filter in Alteryx:
!IsNull([Patient ID])
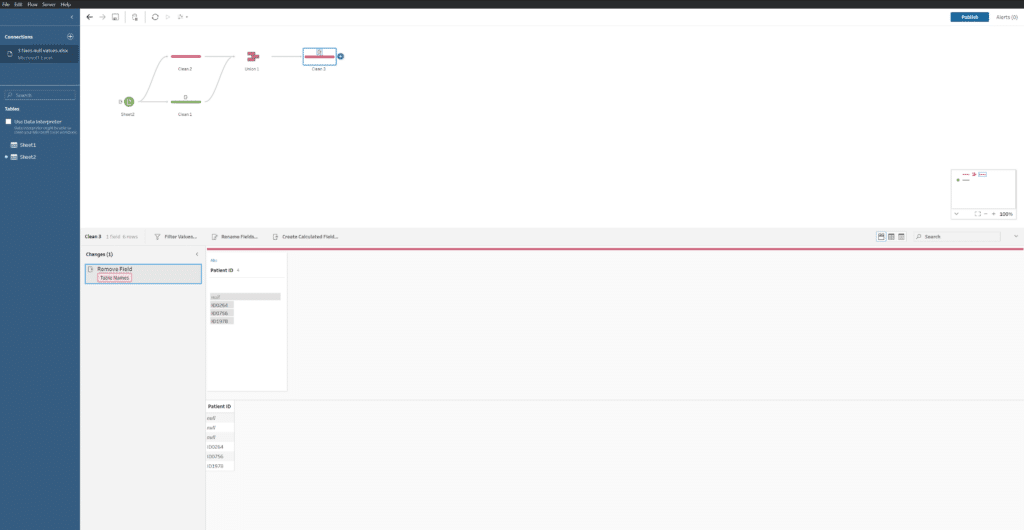
Alternatively here is how you could implement this same tactic using Tableau Prep:
ISNULL([Patient ID]) != TRUE
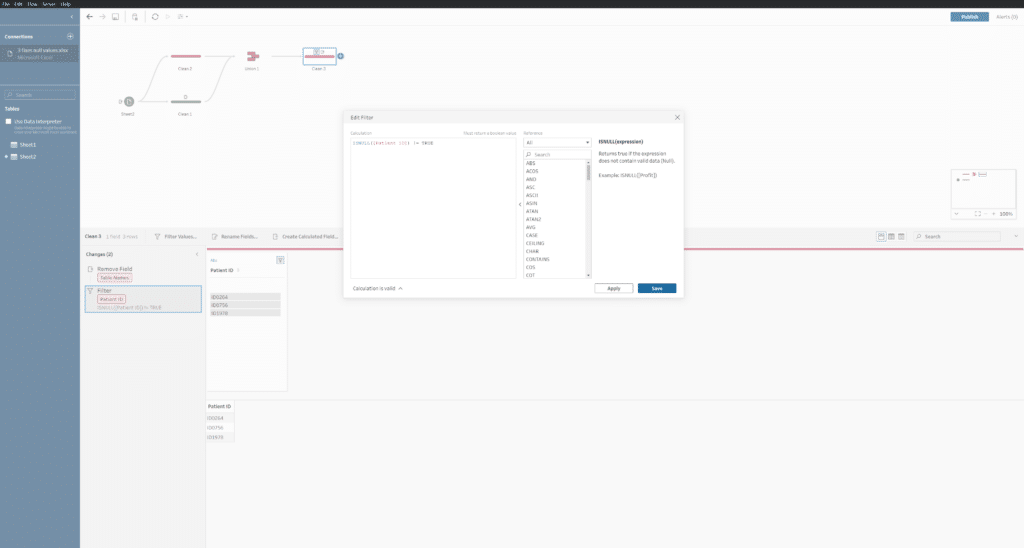
Fix #2
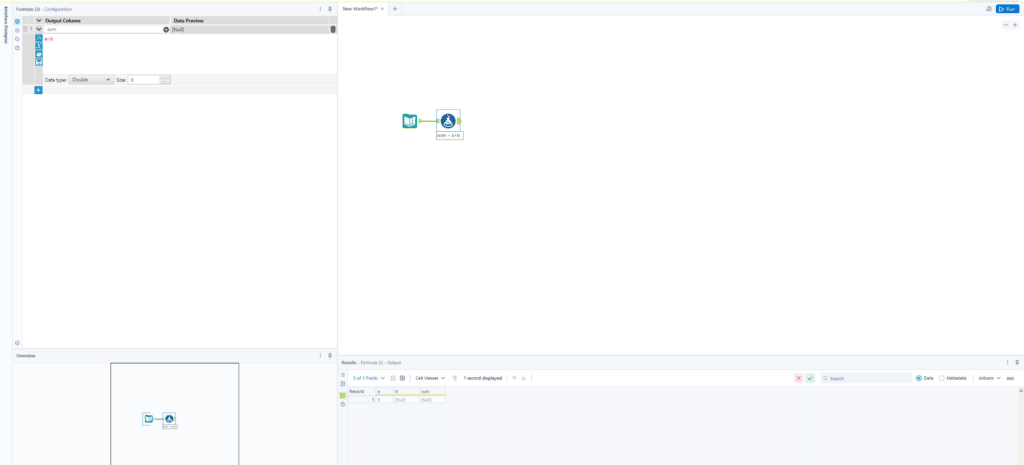
The next way I would address nulls is by implementing some sort of null handling method where those values are replaced with something else using other criteria available to me either in the dataset or through my understanding of the data as a whole. To help illustrate this, let’s say we have a columns that look something like this:
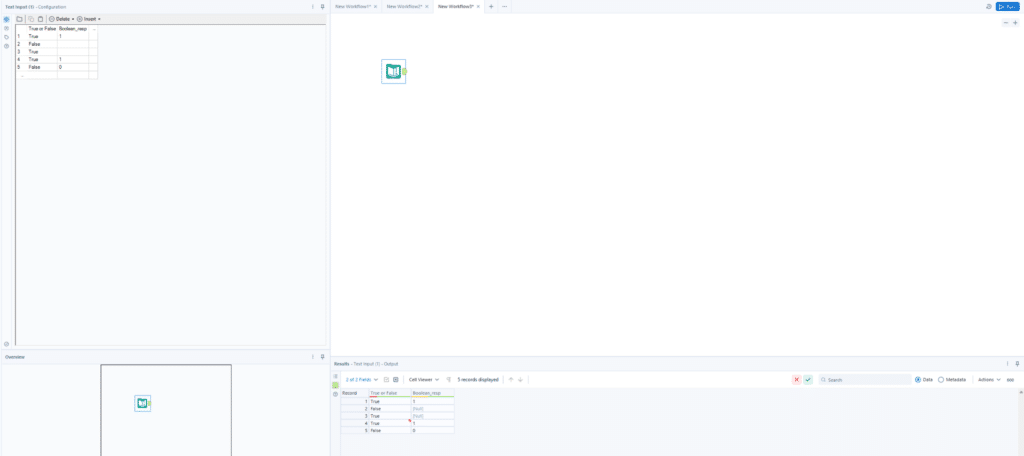
In this example, I have a column called “True or False” and another column called “Boolean_resp”. As we can infer from the image, “Boolean_resp” seems to tie to the value in the “True or False” column with either a 0 or 1 to indicate whether it is true or false. Now we do have some nulls here but we have values in the base “True or False” column. Using null handling, I could create a formula that looks like this to help correct whenever the “Boolean_resp” column is null so that I don’t have to worry about any missing values in that column as I continue developing:
In this example I have a column called “True or False” and another column called “Boolean_resp” as we can infer from the image, “Boolean_resp” seems to tie to the value in the “True or False” column with either a 0 or 1 to indicate whether it is true or false. Now we do have some nulls here but we have values in the base “True or False” column. Using null handling, I could create a formula that looks like this:
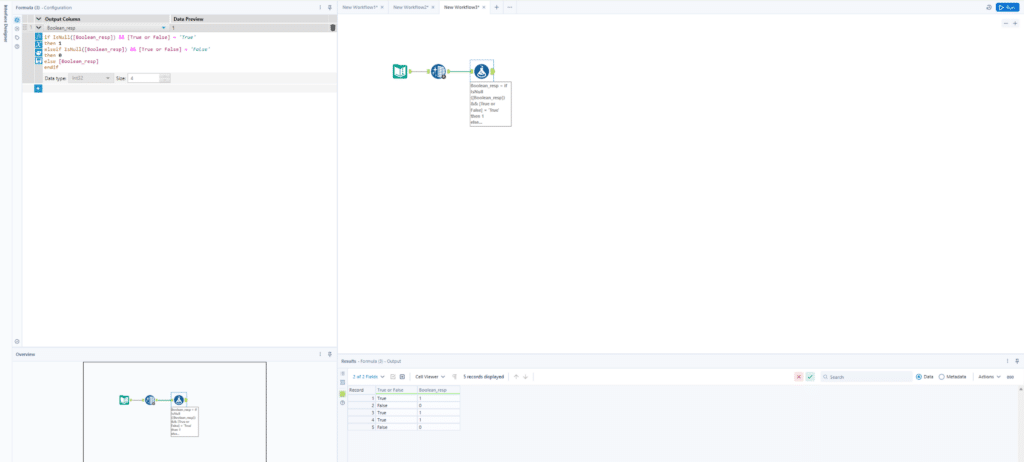
Null handling in this manner helps correct whenever the “Boolean_resp” column is null so that I don’t have to worry about any missing values in that column as I continue developing. Note that it is important to clarify with both your end users and the source that you gathered your data from, that the assumptions you are making with any null handling formulas are accurate in order to ensure data integrity.
![]()
Fix #3
Lastly, another way to minimize null values revolves around unioning datasets together. As we discussed before, a union is a very common way to create nulls if the schemas being unioned are not identical or configured correctly. Here is what the result may look like if your schemas do not align before unioning them together:
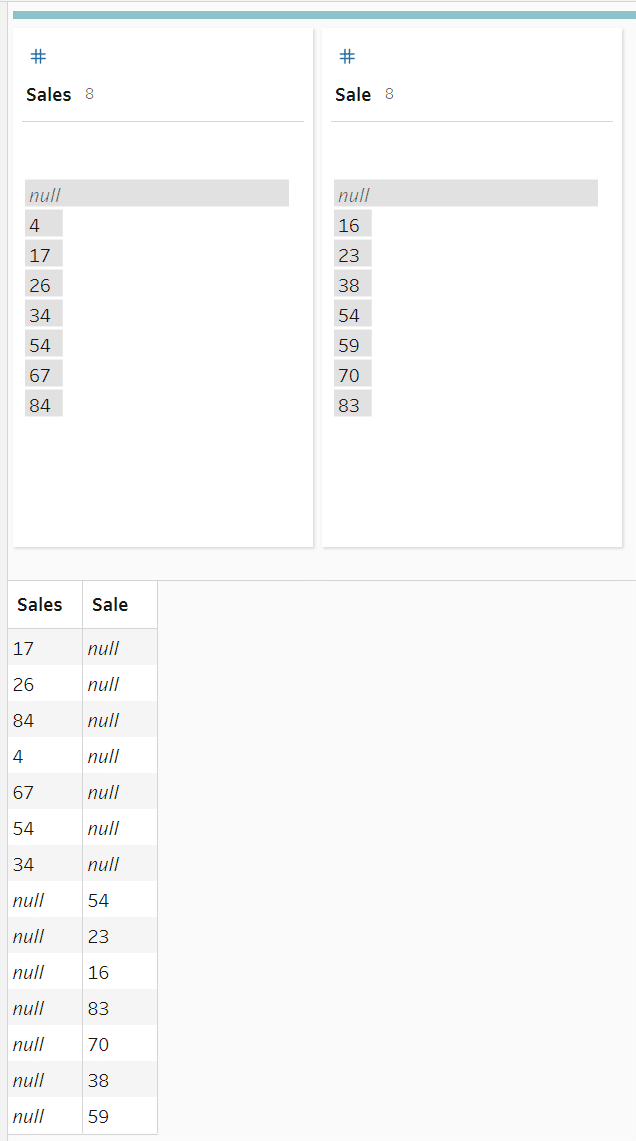
As you can see in the above example we have both a “Sales” and a “Sale” column that is null when the other has values and vice versa. The best way to handle this is to first confirm that those columns represent the same thing in the context of the dataset and if they do, then decide on one consistent naming convention and implement that amongst all of your data sources.
If you learn that they represent different values and cannot be consolidated, then I would recommend using null handling to update the values so that they show that no data was provided for the null rows.
Summary
While null values are a common occurrence when working with data, especially larger datasets, they are easily fixable with some small updates to your workflow or calculations. Now that we have covered three different ways to handle nulls, I hope you will give some of these a try in your next data project. As always thank you so much for reading and be on the lookout for more data engineering related content coming to Playfair+ over these next few months!
Best of luck!
Nick

Written By
Nick Cassara

Peer Review
Ethan Lang
Director, Analytics Engineering
Related Content
The Fundamentals of Data Engineering
The fundamentals of data engineering are centered around, well, data. With data becoming one of the hottest topics in the…

Nick Cassara
A guide to using Tableau Prep Builder to explore data This video will cover using basic techniques in Tableau Prep…
3 Tips for Data Quality Assurance (QA) in Alteryx

Anyone who works with data would probably say that ensuring accuracy is half the battle. While a final Quality Assurance…