Data Lake vs Data Warehouse: What’s the Difference?

With the vast amount of data available today, many organizations are assessing their data solutions and making decisions to support the integration of AI into the business. AI and big data analysis require a solid data foundation to work from. To prepare for the enhanced data needs, many organizations are reassessing their database servers and beginning to implement data lakes and data warehouses. But which one should replace the traditional database? In this post, we will compare the data lake vs data warehouse.
Data lake
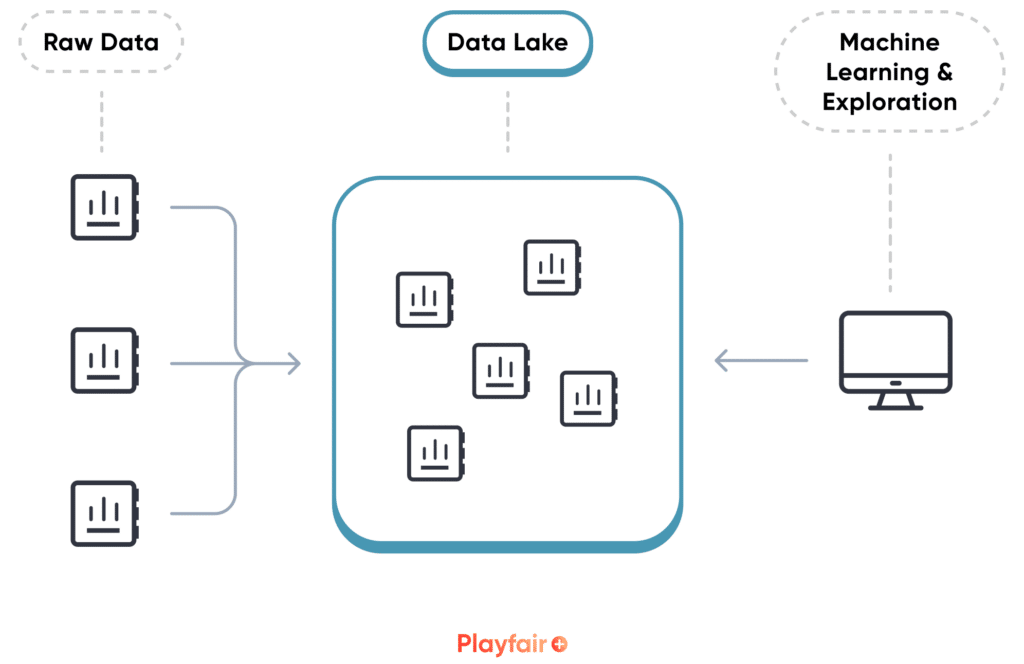
As the name suggests, data lakes are usually described with the lake analogy. They can be thought of as a vast body of water that holds all of the data in a raw, unstructured way. Most data lakes can handle a variety of different data types, from the traditional spreadsheets and tables to unstructured images and videos. The data is stored in its unprocessed forms, also known as blobs or objects, as structure is not needed by a data lake. Because data lakes use object storage, they are known for scalability as they can handle large amounts of data at rates typically cheaper than a traditional database.
![]()
Continue reading with a free account, or login.
Unlock this tutorial and hundreds of other free visual analytics resources from our expert team.
Already have an account? Sign In
By continuing, you agree to our Terms of Use and Privacy Policy.
A data lake stores objects using metadata tags. These tags are used to locate objects within the data lake, and are therefore extremely important when storing objects in the data lake. Metadata tags are similar to keywords and they are attached to each object. They range anywhere from descriptions of the object to including custom items like the business area to which the object belongs. For example, uploading an Excel file containing the employees of the company may have tags like Format: Excel, Size: 100MB, Department: Human Resources, Schema: employee_names, and/or Confidentiality: Medium. A tagging system should be developed to ensure tags are consistent and automated whenever possible. There are many ways to apply the tags to the objects in a data lake, such as, during the ETL process, manually, embedded within files or uploading a separate metadata file, built in functionality within the data lake platform, and/or through the data catalog.
A data catalog is a centralized repository that can help with data lake organization. It acts similar to a library system, where a user could search by keyword, or tag, in order to find related objects within the data lake. Schemas are another way to organize the data within the data lake and can be applied either when writing the data into the lake or when reading the data out. Schemas are a structure for the data and are typically rigid with its specifications. Because of this rigidity conflicting with the fluid nature of a data lake, schemas should be used sparingly and are typically only recommended for specific analytic use cases.
To push data into a data lake, an extract, transform, and load procedure, more commonly referred to as ETL, will need to be implemented. This process will extract the data from the source system, transform it with any cleansing necessary, and load it into the data lake with tags. Building the data pipeline will be dependent on the data and use case, there is no one size fits all and each ETL process is usually a blend of different methods. With a data lake, the focus is on loading the data rather than structuring it and because a data lake does not require a schema, the data cleansing process will not be as intensive.
Tableau Prep Builder and Tableau Prep Conductor for Data Automation
The data can be pushed either by streaming or batching. Streaming is when the data is pushed to the data lake as it comes in, also known as real time processing. This methodology is more resource intensive and would be the best method for data that needs to be analyzed immediately, such as gaming data, fraud detection, etc.. Batching is pushing the data to the data lake through an offline process after some data has accumulated. For example, pushing sales data at the end of each day, or payroll data pushed weekly. Batching is less resource intensive and a better option for large datasets.
Data lakes can be on premise and/or cloud based. Most data lakes are designed to utilize multiple servers or nodes, which allows for parallel processing. The data is stored into smaller units across these multiple nodes and queries will be split across the nodes as well so that they can run at the same time. In some instances, each node can also contribute its own processing power. Parallel processing helps increase speed and the handling of big data and complex calculations, while also being scalable through its ability to continue to add additional nodes. As for security, an organization will need to put in additional strategies and resources into security features, as typically this is not built in due to the unstructured nature of the data.
In summary, a data lake can be helpful when you need a space to flexibly store different types of data, or large amounts of unstructured data. Data lakes are built for exploration, which makes them the preferred solution for machine learning analysis.
Data warehouse
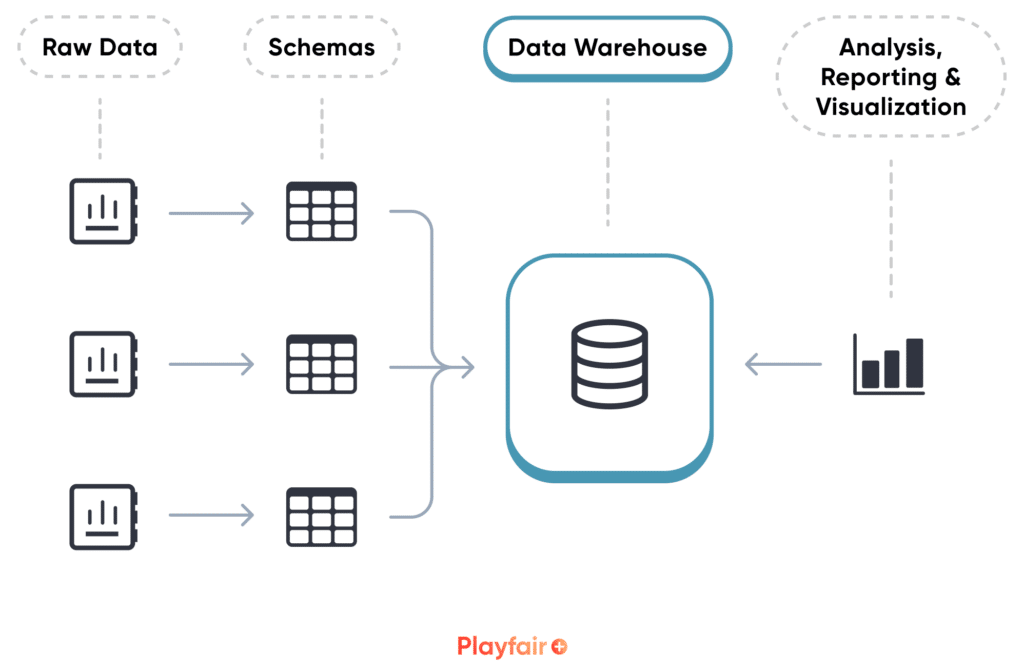
A data warehouse is a more structured way to store data and has many options for organization. Anything from being organized by business area or use case, to normalization, to different schema techniques are used to store data. Data warehouses typically require a schema when storing the data and the data is then stored in columns of similar data types. Along with the structured and pre-planned organization, data warehouses also allow for metadata to help describe the data.
Unlike the data lake, which would use the metadata to query, the data warehouse will sort through the stored columns to pull back data. This makes querying more efficient than a traditional database, which would normally search by row. Searching by column is quicker because it is having to search through far fewer options than by every row of data. A data warehouse can also partition tables and utilize indexes, further optimizing query performance. In addition to the schemas and metadata, a data dictionary may be useful for a data warehouse to further help end users understand and find the data.
![]()
Data warehouse servers were traditionally on premise, but have been expanding into cloud based servers or even a hybrid of the two. The enhancements in technology are allowing data warehouses to also take advantage of parallel processing for speedier queries. With a data warehouse, it is becoming increasingly common to ensure that BI tools are able to connect to the data warehouse to provide a more user-friendly interface.
As for the data pipeline, because a data warehouse needs a schema and structured, consistent data, the ETL process is much more robust than what is required by a data lake. The ETL process usually includes cleansing, prepping and validating the quality of the data before pushing into a data warehouse. Due to previous limitations of technology, a data warehouse was mostly used for historical accounts of data. Now, with the more modern servers and platforms, data warehouses can handle both batching and the real time streaming of data, though streaming is still more resource intensive and should only be used for use cases that require real time analysis.
Because of the very structured nature of a data warehouse, security is one of the strengths. A data warehouse can have data security elements such as user access and data encryption. Many data warehouse platforms provide built-in compliance features as well. In addition, because of the robust ETL processes, there are typically more traceable data lineage logs, which can also help with compliance and security requirements.
How to Implement Column-Level Security in Tableau
In summary, a data warehouse should be implemented when you need structured and reliable data. This is usually driven by any analysis needs within the business and may be especially important if there are end users of various roles and levels trying to leverage the data. The schema requirements create a more organized system to quickly find data in a cleansed and consistent format.
Summary
So what is the best option when considering a data lake vs data warehouse? It all depends on the incoming data and outgoing analysis requirements. For large amounts of data that is unstructured and needs to be pushed into a centralized environment quickly, a data lake should be considered. If data structure, integrity and organization is important, a data warehouse would be the better choice.
For analysis, the data lake’s ability to process complex queries that explore relationships amongst data makes it a good option for exploration and machine learning. If the end users are business segments who know what they want, or may be using the data for reports or data visualization, the structured schemas of a data warehouse would serve the business better.
Perhaps the answer is both? With the continued enhancements in technology, many data lake/data warehouse platforms allow for both structures. This hybrid approach would have the data stored unstructured within the data lake and then moved into the data warehouse through an ETL process for end users to access. However, this option may require additional resources, additional planning, and higher costs.
With any of these approaches, thorough planning is required. An organization will have to assess their needs, resources and budget and choose the best fit for their business. As technology continues to improve and more vendors allow both data lakes and data warehouses within the same platform, we may see a trend towards more hybrid approaches in the future, potentially eliminating the data lake vs data warehouse choice altogether.
Thanks for reading; you’ve got this!
Ariana

Written By
Ariana Cukier

Peer Review
Nick Cassara
Manager, Data Engineering
Related Content
An Introduction to Alteryx Generate Rows
The Generate Rows tool in Alteryx is a great tool to explore when you need to expand your dataset. When…
9 Quick Alteryx Tips to Optimize Your Data Workflows
When beginning to develop an Alteryx workflow, sometimes I find myself asking, where should I start? What happens next? How…
Visual Analytics Trends for 2024

Portions of this post originally appeared on LinkedIn. Follow us on LinkedIn for frequent updates on visual analytics trends and…